History of Library
Versioning Standard
0.15.2-FB
DateView 테이블 표기 방법 변경
이전 기본값
TABLE join(file.tags, ", ") AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 5
컬럼이름 default File에서 POSTS로변경
TABLE WITHOUT ID
file.link AS "POSTS", join(file.tags, ", ") AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 5
출력되는 태그를 모든태그에서 직접적인 2가지만 출력으로 변경
TABLE WITHOUT ID
file.link AS "POSTS", join(slice(file.tags, -2), ", ") AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 5
출력되는 파일중 긴이름인 Hompage나 History of Library는 제외
TABLE WITHOUT ID
file.link AS "POSTS", join(slice(file.tags, -2), ", ") AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
AND file.name != "History of Library"
AND file.name != "Hompage"
SORT file.mtime DESC
LIMIT 5
0.15.1-FB
Dataview tag표기방식을 여러줄에서 inline 한줄로 변경
문제: 테이블 표기시 태그들 때문에 한번에 보기가 힘듬
해결: dataview 문법에서 join함수를 통해 한줄로 표기
TABLE file.tags AS Tags -> TABLE join(file.tags, ", ") AS Tags
```dataview-script
TABLE join(file.tags, ", ") AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 5
```
변경 전

변경 후

참고링크: https://www.reddit.com/r/ObsidianMD/comments/17jlhku/inline_dataview_query_to_display_list_of_tags/
0.15.0-LB
I was testing a Python module that writes tags and ended up deleting all of my tags, so I took this opportunity to clean up my library categories.
When I tested the program to see if I could delete it, I realized that not only the tags that I could see were deleted, but also the tags that Varcel, the distribution platform, wrote itself, and the platform stopped working.
It took me a while to find the error, and then a few days to recover from it, as it overlapped with Varcel's limit of 100 deployments per day.
So, I thought I'd take this opportunity to reorganize the categories, both the ones that were too granular and unnecessary when I started, and the ones that are really unique to me.
0.14.0-LB
I've set a quality standard for writing articles: unique and personable.
The reasoning behind this is that I'd rather write one article that people read than 100 articles that they don't read.
Especially because if you write the same stuff that comes up in searches anyway, it's a waste of time because it's buried by higher quality articles.
In other words, it's better to have one good post than 10 bad ones that don't give anyone any direction.
The standard for writing is that your own traces should be revealed in your writing.
0.13.0-FE
Show description frontmatter by custom component
reference: https://dudethatserin.com/advanced-tips-obsidian-digital-garden/
code
naviage here src/site/_includes/components
create this file user/notes/header/frontmatter.njk
read description front matter from note , and write to header

0.12.0-LB
Using base template from local. Because speed and Tokens. It will be longer after, so that base knowledge is useful more than external vector db.
By Regex pattern.
I decided to only articles is going to embed to vector. Because using just categories are enough to only base
0.11.0-LB
Write a description of all my data. simplest, most important and most manual tasks
Every file that goes up in a library has a description. This gives us a summary of the information, but this property was created after we had quite a bit of data.
So it's all manually entered. It's too laborious to automate. But it's still my philosophy to do it by hand. In the case of this app, the goal is to "let you know the author's thoughts", so it would be less pure if the description was written by an AI. That's not to say that I didn't use translation AI, but I checked every description.
I want to make sure that I can best explain my intentions and what the purpose of this category, this document, is.
0.10.0-PY
Changed base_template content to be imported locally to the vector DB
Before: Get base_template file string from local file
def invoke_from_retriever(query, llm, prompt_template, vectorstore , uuid=''):
...
setup_and_retrieval = RunnableParallel(
Library_base_knowledge = RunnableLambda(lambda _: load_base_template(BASE_FILE_PATH)),
Library_base_knowledge = RunnableLambda(lambda _ : knowledge),
history_conversation=RunnableLambda(lambda _: history), # Use RunnableLambda for static content
input=RunnablePassthrough() # This can just pass the question as is
)
return history, query, answer
def load_base_template(file_path):
try:
return Path(file_path).read_text(encoding='utf-8')
except FileNotFoundError:
return ""
After: Get base_template file string from vector DB ,Simplify by removing functions and using variables
def invoke_from_retriever(query, llm, prompt_template, vectorstore , uuid=''):
...
expr_base = f"source == '{BASE_FILE_PATH}'"
retrieverOptions_base = {"expr": expr_base , 'k' : 1}
pks_base = vectorstore.get_pks(expr_base)
if pks_base:
retriever_base = vectorstore.as_retriever(search_kwargs=retrieverOptions_base)
knowledge = retriever_base.get_relevant_documents("base_query")[0].page_content
else:
knowledge = "No base template in vectorstore"
print("knowledge\n" + knowledge)
# Set up the components of the chain.
setup_and_retrieval = RunnableParallel(
Library_base_knowledge = RunnableLambda(lambda _: load_base_template(BASE_FILE_PATH)),
Library_base_knowledge = RunnableLambda(lambda _ : knowledge),
history_conversation=RunnableLambda(lambda _: history), # Use RunnableLambda for static content
input=RunnablePassthrough() # This can just pass the question as is
)
return history, query, answer
full code
def invoke_from_retriever(query, llm, prompt_template, vectorstore , uuid=''):
expr = f"source == '{uuid}'"
retrieverOptions = {"expr": expr , 'k' : 1}
pks = vectorstore.get_pks(expr)
print(f'pks: {pks}')
if pks:
retriever = vectorstore.as_retriever(search_kwargs=retrieverOptions)
history = retriever.get_relevant_documents(query)[0].page_content + "\n"
else:
history = ""
expr_base = f"source == '{BASE_FILE_PATH}'"
retrieverOptions_base = {"expr": expr_base , 'k' : 1}
pks_base = vectorstore.get_pks(expr_base)
if pks_base:
retriever_base = vectorstore.as_retriever(search_kwargs=retrieverOptions_base)
knowledge = retriever_base.get_relevant_documents("base_query")[0].page_content
else:
knowledge = "No base template in vectorstore"
print("knowledge\n" + knowledge)
# Set up the components of the chain.
setup_and_retrieval = RunnableParallel(
Library_base_knowledge = RunnableLambda(lambda _ : knowledge),
history_conversation=RunnableLambda(lambda _: history), # Use RunnableLambda for static content
input=RunnablePassthrough() # This can just pass the question as is
)
# Construct and invoke the chain
rag_chain = setup_and_retrieval | prompt_template | llm
answer = rag_chain.invoke(query).content.rstrip("\nNone")
return history, query, answer
`
0.9.1-FE
before

after
img -> Eliminate floating right
link eliminate new line and make it to inline
/* Prevent markdown link line breaks */
.markdown-rendered a {
display: inline; /* Default inline display for links */
white-space: nowrap; /* Prevents the text within the link from wrapping */
}
/* Adjust image width and maintain aspect ratio */
.markdown-rendered img {
float: none !important; /* Ensures the image does not float */
display: block; /* Displays images as block-level elements */
margin-left: auto; /* Centers the image horizontally */
margin-right: auto;
width: auto; /* Allows the image to maintain its original width unless it exceeds the maximum width of the container */
min-width: 50%; /* Sets a minimum width for the image; adjust as needed */
max-width: 100%; /* Ensures the image is not wider than its container */
height: auto; /* Height is automatic to maintain the aspect ratio */
}
/* Override and reset any float styling specifically for images */
.markdown-rendered p img {
float: none !important;
}
blockquote:before {
content: none; /* No content before blockquotes */
}
0.9.0-PY
stramlit_app.py
RAG_Milvus.py
create_base_template.py
An introduction to the whole process
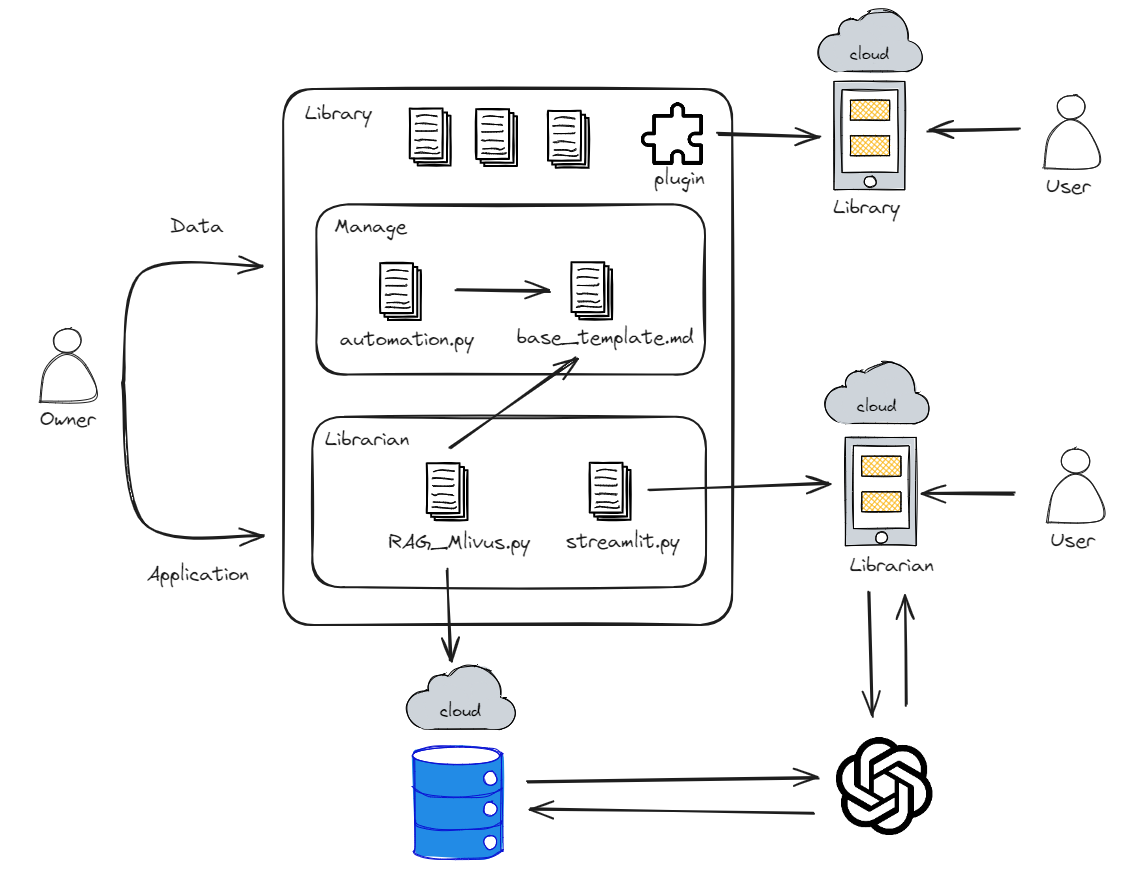
Web platform
Write posts (a md file) in the Entrance directory as inspiration strikes.
Automatically tagged, repositioned when running automation.py
Deployed via plugin to https://www.murphybooks.me/
- Data management. MD file text-oriented personal IT blog
- Data is put into the Entrance folder. Using automation.py to automatically tag (link backlinks), automatically create folders, and move files.
- The categorization is done by creating a call number index.md file, This md file is converted to json, and the system works according to this json format.
- So the most important thing is to have filenames (major,minor,sub,book) that match the rule name in the directory (Entrance) that matches the policy.
- Create base_template.md based on the files in the web platform. This file is the primary parent file for the RAG and has path and description values for all file
Application process.
If the user doesn't have a session when they enter, create the first session and answer based on base_template.
If a session is confirmed later, it recognizes the previous content as history and the current content as current conversation.
If there is a special pattern of file_path: ... .md, it answers by summing the queried values.
That application is serviced by Streamlit cloud that free deploy service https://murphybooks.streamlit.app/
- implement RAG with Langchain.
- Data (md, txt file only)
- Use invoke function to get query value using prompt_ template
- Use openai embedding for embedding
- Insertion (important considerations speed, time, cost)
2. file-by-file insertion. Update for one article
3. Folder embedding. When updating several at once
4. Per-user memory insertion - Memory
- Use Milvus Vector DB and use the cloud
- Implement your own upsert function
- Connect with Milvus' own function
- Lookup
- Use source value as a key. The key is divided into two types
- When uploading web platform data directly, the file path is treated as SOURCE
- Treat UUID value as SOURCE in a conversation session with a user
- Data (md, txt file only)
- Implementing front via Stramlit
- select model (A radio button)
- input (text box, and A hutton)
- admin screen (Password with streamlit secret)
Centralized management as much as possible in the form of files. Environment values , packages
For security reasons, but also for management reasons, it was better to create and manage environment variables in .env files as much as possible.
When using external solutions like streamlit, you need to use toml to use secrets, but it is convenient to use .env directly with copy-paste.
It is good to manage requirements in the form of requirements.txt to use cloud deployment systems and to maintain virtual environments such as conda.
Additionally, I feel that visibility is much better if it is displayed through comments.
Use managed services as much as possible
As I was working on the project by myself, I had to manage a lot of things, so I decided to use managed services. The downside is that you become dependent on the managed service or need to do extra work, but it's better in the long run. On a small scale, to be precise.
For example, for the web platform, I build it through the Obsidian plugin and deploy a certain number of times a day through the Varcel homepage. While using this, there were problems such as not knowing the daily distribution limit of varcel, or not knowing how to set up the domain when setting up, but despite the glitches, Using it is better than not.
The biggest advantage is requires less infrastructure management work and no cost
Another platform I use is streamlit cloud.
On the downside, I had to manually register a secret value in the requirements.txt and ui to get the service. At first, I didn't know how to do this, so it was a bit laborious, but once I succeeded, it was easy to maintain because I only needed to update incrementally. This is also a good way to go because it reduces infrastructure management.
Another managed service is a serverless managed service provided by a cloud company called zilliz for milvus vector db. This is what I found after considering VectorDB to configure memory, but then realizing the volatility of the service when it goes down and the cost of infrastructure to maintain adequate memory.
Start as simple as possible and work your way up to complexity
There are several cases that I solved by starting simple rather than overcomplicating the project, and there are three main ones.
The first is a data form. At first, I considered full automation, where you just throw in content and it automatically creates a file title with a number, tags it, and so on, but this was too complicated and didn't work well.
The logic was too complicated to start working easily. So I made a promise to myself and the system to keep it simple. The filename should be written in alphanumeric English according to a set policy, which should match the converted json by a predefined call number index.
Since I was working on my own, I didn't need to complicate the logic that much, and in the end, the simple logic worked and So I can able to start the project.
Second is the authentication method. I was worried about how to handle authentication in a situation where an admin page is required. Should I use authentication in stramlit itself. At the end, I made it work if it matches a certain hard-coded pattern. I had a lot of questions about base64 encoding, where to store it, and whether it would be exposed when using commands like echo, but I decided to simply use streamlit's sercret function to hide environment variables. The main reason that i can make this decision is that even if it is exposed, the maximum loss is limited to invoking the openai api, which is within my budget (about $20).
Third is the session delivery method. Once you have a conversation, it is recorded as a session via a UUID. This is important because it allows you to continue the conversation later, and it is possible to continue the conversation with this recorded information. The question was how to store and manage this information. It needs to be personalized to prevent it from being seen by others, and it needs to be separated by user, which can lead to complex logic and additional infrastructure.
My solution was to simply leave it up to the user.
The UUID, which is session information, disappears when the session is closed, so there is no need to manage it, and if the user manages it, it becomes personalized private management, so the part I needed to prepare was to implement logic in a way that handles the provided UUID. Of course, the best way is to provide this management in a secure form through SSO or at least use a guest ID so that the user does not do it, but in that case, I think I will have to spend all this quarter on DB Schema work for user management, so it is an unavoidable choice...
The most important thing is to leave it to others and cut it off appropriately
This is probably the most important point to complete the project.**
**
Leaving it to someone else means implementing the features you need, but recognizing the improvements that can be made and leaving them for someone else in the future.
For example, let's talk about .env files in more depth. The whole reason I started talking about .env was that I wanted to manage environment variables in a centralized system that was safe, easy to manage, and had a low learning curve.
To put it more simply, environment variables should be managed in a single file, accessible from anywhere, with a low learning curve, and we should spend less money and time running this system.
So at first it was an .env file, but when I was doing it on more than two environments, I felt that I needed a centralized system in case it grew by n times, so I looked for solutions like hashicorp's valut or AWS's parameter store. But I wanted to be a little greedy and reduce the learning curve. For example, hashicorp valut requires me to manage the infrastructure, and in the case of AWS, the container I run must have the aws command installed, and I need to manage the aws key in addition.
So in the end, I decided to proceed with the .env file, and the rationale was that I felt that I could proceed only if I thought that someone would take care of this part. However, the concern I have about this part is that if it grows to more places in the future, I will need an additional appropriate system.
Cutting it right means you don't have to implement it too perfectly
Another important point, proper separation, is something I learned while implementing Milvus's upsert function. In implementing the upsert function, I found out from the docs that there is a very good function that, as the name suggests, updates if there is data and inserts if there is no data. However, there was a problem that did not work properly in the first place. It didn't work properly because it conflicted with the function that automatically creates another parameter, priamary key, so I looked at the pymilvus package of mivus, which actually references upsert, and I looked at the docs and issues, but actually, logically, in my environment, where I don't care if the PK is not maintained, if I implemented it in the form of deleting the existing entity if it exists and creating it if it doesn't exist.
I could implement it in less than 2 hours. However, I was obsessed with the need to use upsert and overinvested for about 12 hours or more, and in the end, I ended up implementing the aforementioned delete and insert method.
This was a lesson learned after the fact because it was cool to break things properly.
Make good use of logs
You can get lost a lot while building. It could be something I did wrong (variable name location, etc.), something the docs did wrong, or something that's hard to find in the docs or error messages.
In particular, this environment is a structure that references streamlit in an environment that references milvus, which references langchain. Therefore, as a first-time user of the three, when I encountered a problem, it was difficult to figure out whether langchain corrupted the return value, the milvus function behaved strangely, or the streamlit notation was strange.
For example, langchain and milvus would return a string with '₩n' in it, but streamlit would automatically ignore it,
No matter how much I edited the streamlit UI, I couldn't get a value because Milvus returned an empty value in the first place...
This time, I made it simple by using the print function, but later, I felt that it was better to create an error log function and utilize it as a decorator to basically check the log for the first part of the operation.
There are still many regrets, but minimizing packages to speed up the app, not adding new lines when the user enters text, saving the memory session more visible and adding the current memory session, adding one more prompt template to increase the correct answer rate for the article, etc.
Still, in the end, how much? I think it's an important branching point to make a product that works, so I think the criteria for becoming 1.0.0 is "returning to the initially intended process form" even though 0.9 is the version.
0.4.0-PY
create template file for initial RAG state
Before we implement RAG, we want to break it down into two stages. After all, when we first implement RAG, we will be passing the context in the form of an LLM, which is inefficient in terms of speed and ocst if it contains all the content.
First stage without content (000.010,010.00 etc.) and second stage with content (010.00 a, 010.00 etc.)
Create a file that only knows the descriptions of the files containing content files by pulling their filenames and descriptions from the first stage.
What we've updated in this version is a python file that creates a template for the primary stage
The important things in that file are paths and Regex.
Executable path some_path/Managed/create_base_template.py
Reading path some_path/Library/Managed/...
Writing file path some_path/Managed/Librarian/template.md
It's important to make sure the path is readable, and which regular expression is used to read the file.
The module has two functions
The first one extracts the description. The main point is to extract the content from the footer via r'^---\n(.*?)\n---' and then extract the description via metadata.group(1), i.e. the data must be in the promised format.
The second is recursively searching through rglob and returning by mdfile starting with 3 digits via regular expression
0.3.4-LB
Using gist for centralized management for code snippets
WYSIWIG
Key point is .pibb. for using my web
iframe tag src="https://gist.github.com/murphybread/a0a351e489cde4b2064fcd3a7855d885.pibb?file=automation.py" width="100%" height="300"
/iframe tag
0.3.3-PY
Overwrite the article's tag line
Modify exist add_tags_to_md_files function
What i want to do is overwrite the files' tag line. It is because a new tag is being added to an already existing tag
So I modify this part. first get distinguish body. by the split function divide tag and contents. And Combine these properly
if "---" in content and new_tag:
parts = content.split("---", 2)
if len(parts) == 3:
header, middle, body = parts
body_lines = body.split('\n', 2)
modified_body = f"{new_tag}\n{body_lines[2]}" if len(body_lines) > 1 else new_tag
new_content = f"---{middle}---\n{modified_body}" # Reassemble the new content
f.write(new_content)
f.truncate() # Remove the rest of the old content
print(f"Added tag to {new_tag}")
0.3.2-LB
Two template post formats, depending on whether the content has a source or not
Template 1: For Content with a Source
Template 2: For Content without a Source
0.3.1-LB,OB
Structural management from one file
In the case of in obisidian's markdown grammar, it is called Wikilink, which shows the contents of the linked note. In other words, the mirroring method makes the two structures managed by Homepage and call-number-index manage in one place
The result is easy to implement and easy to manage afterwards
0.3.0-LB,PY
This is what I want to do.
major md file tags #[[800]]#test_major
minor md file tags #[[800]]#test_major#[[810]]#test_minor
sub md file tags #[[800]]#test_major#[[810]]#test_minor#[[810.00]]#test_sub
books md file tags #[[800]]#test_major#[[810]]#test_minor#[[810.00]]#test_sub#[[810.00 a]]#test_book
3 steps
Checking
Use Regex
major_regex = re.compile(r'^([0-9]{1}00)\.md
### Making code
Think about data
when not major, convert major
when sub or book, consider position of function argument
```py
major_code, minor_code, sub_code, book_code = "", "", "", ""
if major_regex.match(file_name):
major_code = major_regex.match(file_name).group(1)
elif minor_regex.match(file_name):
major_code = minor_regex.match(file_name).group(1)[:1] + '00'
minor_code = minor_regex.match(file_name).group(1)
elif subcategory_regex.match(file_name):
major_code = subcategory_regex.match(file_name).group(1)[:1] + '00'
minor_code = subcategory_regex.match(file_name).group(1)
sub_code = subcategory_regex.match(file_name).group(2)
elif book_regex.match(file_name):
major_code = book_regex.match(file_name).group(1)[:1] + '00'
minor_code = book_regex.match(file_name).group(1)
sub_code = book_regex.match(file_name).group(2)
book_code = book_regex.match(file_name).group(3)
Making tag
If you know how to use get for recursive contents in JSON, function become very easy
Understanding data structures and creating variables with JSON enables this recursive structure
tag = ""
if major_code:
major_info = json_structure.get("MajorCategories", {}).get(major_code, {})
tag += f"#[[{major_code}]]#{major_info.get('title', '').replace(' ', '_')}"
if minor_code:
minor_info = major_info.get("MinorCategories", {}).get(minor_code, {})
tag += f"#[[{minor_code}]]#{minor_info.get('title', '').replace(' ', '_')}"
if sub_code:
sub_info = minor_info.get("Subcategories", {}).get(f"{minor_code}.{sub_code}", {})
tag += f"#[[{minor_code}.{sub_code}]]#{sub_info.get('title', '').replace(' ', '_')}"
if book_code:
book_info = sub_info.get("Books", {}).get(f"{minor_code}.{sub_code} {book_code}", "")
tag += f"#[[{minor_code}.{sub_code} {book_code}]]#{book_info.replace(' ', '_')}"
print(major_code, minor_code , sub_code, book_code)
return tag
0.2.3-OB
Change dataview query
TABLE file.name AS title, file.path, file.mtime
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
Add Table attrivutes modifed time path and remove link
Specifify query path "Projects/Library"
Increase Limit to 7
0.2.2-LB
Using GitHub to Share Synchronized Python Files Across Different Platforms
Problem
The current Obsidian sync functionality only supports synchronization for files with Python file extensions, excluding files in other formats such as Markdown (md).
Initial attempts involved converting Python files into Markdown (md) or inserting Python code into Markdown files. However, this approach resulted in excessive fragmentation and posed challenges for management.
Solution
https://github.com/murphybread/Library
To address this issue, the solution is to utilize GitHub links for syncing files between different platforms, such as Mac and Windows. This can be achieved by performing a 'git pull' to ensure synchronization with the latest version when starting work through the GitHub link.
0.2.1-PY
dg-publish frontmatter position
Problem
Notes not showing up on the homepage
Reasoning
There are some things that work and some things that don't, and in particular, there is a 404 in the case of the latter, so it seems that there is a problem with publishing.
If the tag of the note that doesn't work is separated by a line like this, it is judged as a problem.
problem form
---
dg-publish: true
---
Solution.
Tested some notes by moving the tags as follows and confirmed normal operation.
Then I added a function called update_content_and_position in the python file.
duplicate_tag.py to automate it.
---
dg-publish: true
---
0.2.0-PY
Change the call number index structure and modify the convert file
Problem
obisidian use ![[filename]] preview of note, but line break and indentation was wrong
Major category indent was wrong
As-is Used this structure pattern
[[000]] IT Knowledge
- [[010]] Develop Knowledge
- [[010.00]] Develop Computer Science Knowledge
- [[010.00 a]] Essential Developer Insights
- [[010.10]] Develop Programming Language
- [[010.10 a]] Bash shell
Major Category don't use hypen.
That makes preview error indent and line break
Solution
First Change call number md file like this
- [[000]] IT Knowledge
- [[010]] Develop Knowledge
- [[010.00]] Develop Computer Science Knowledge
- [[010.00 a]] Essential Developer Insights
- [[010.10]] Develop Programming Language
- [[010.10 a]] Bash shell
Second Change convert_josn.py
Important point is just change a little bit. Because I don't want to change output.json, filename, path etc...
only consider point is major and minor category variable.
major_match = re.match(r"- \[\[(\d0\d)\]\]\s*(.*)", line)
minor_match = re.match(r"- \[\[(\d[1-9]\d)\]\]\s*(.*)", line)
0.1.1-PY
Managing Only Programming Files with .gitignore: Excluding Content Files
Problem
In the process of starting git pull first, a conflict issue occurs if there is a change in the content file.
It is appropriate to manage .md files other than .py only using the Sync function of the Obisidan tool.
Solution
- Delete .md files from remove server (when command is worked not delete immedately. you shoud commit and push)
git rm --cached -r "*.md"
- Register files with md extension (fileanme should be `.gitignore)
.gitignore
*.md
if command worked and file is created,
next step is commit and push
git commit -m "Managing Only Programming Files with .gitignore: Excluding Content Files"
git push
0.1.0-LB
automated tag from filename key point
This was hard because it is a backwards and forwards type, so if it is major.md, it is different from minor.md, sub.md, and books.md, and we aimed for a function that gets the value corresponding to the key in the structure.json file and processes it.
So, to simplify things a bit more, we went from filename-based to a situation where the exact filename is strictly enforced by the policy, and then we can automate it appropriately.
The key point is filenames, and only for content files.
Later on, we'll also apply it to uncharacterized category files, but that's for later...
0.0.4-OB
DataView modified
This query is used for Recent Post in homepage.
I delete file.path and add file.tags
tags doesn't display backlink tags
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
0.0.3-PY
Add Tag using structure,json in contents file
Adopting the approach of using filenames to create tag numbers was beneficial.
Upon updating to Dataview , I realized that attaching tags from book contents enhances usefulness.
Consequently, I integrated a 'booksTag' function.
Initially, I experimented with a function from another file, which utilized a 'title' variable.
However, to avoid dependencies, I ultimately developed the function within 'automation.py'.
I then opted to modify only a single function, as adding more could complicate matters. Incorporating the tagging functionality into an existing function proved sufficient.
0.0.2-OB
Modify the table to provide more useful information to the readers.
Easily see which files have been modified, and see the tags they have at a glance
- Change the standard modification time not the create time
file.ctime -> file.mtime - Exclude md file that have the tag
#Library
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library" AND -#Library
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 7
0.0.1-LB
The Library Cleaning
Changing History of Library.md from hardcoding to github gist
Better viewing of code on screen in the UI
Before

After

Initialize
0.0.0-LB
Major: The change creates a new process that may not work with the old process and requires significant consideration. Set version criteria more granularly
Keep major, which generally means not backwards compatible, intact
Minor: The change affects current processes and will require attention in the future. Minors are listed as feature additions. File creation, module additions, etc.
However, some minors may be incompatible. Because they don't mean exactly the same thing
For example, if a Python file in a certain version references example.txt, but you change it to base_template, it will not work in previous versions, but the purpose is for testing purposes, so it is considered MINOR in terms of impact.
Patch: The change is minimal or don't require much attention after the change. especially Patches are improvements such as variable names, bug fixes, refactorings, etc.
The reason for the change is that I didn't have an explicit criterion for considering the version impact, and now it's explicit.
분류
대분류 100,200,300
중분류 110,120,130
소분류 101.10 101.20 101.30
중요한것 방향성, 확장성, 기준, 관리
방향성: 인프라 100, 인프라위에 올라가는 cicd 200, cicd를 활용한 위에 올라가는 또는 고급 300등방향성
확장성: 새 주제나 개념이 번호가 붙을 때 중간에 밀어내야하는 경우 ex) 110(A) 120(B)에서 110(A) 120(C) 130(B)으로 확장할경우 110(A) 111(B) 120(B)를 통해 유연하게 확장 가능
-> 이전 버전인 101,102형태면 불가
유사 분류는 뒤에 알파벳을 붙임. 즉 알파벳의 경우 일부러 방향성을 정하지 않음. 110에 해당하지만 그렇다고 110.1처럼 하위로 나누기는 애매한거에 붙임
기준: 확장성을 살려도 110이나 120에대한 개념이 바뀌면 안되기에 최대한 신중하게 골라야 가능. 예를들어 111에 못넣고 기존의 120을 대체해야하는 경우, 기존의120이 121로 밀리게됨 즉 추가가 아니라 기존 데이터도 변동
ADD-Ons
Guest book
problem: record reaction of users in all notes
solution: using external service joey
| Feature | Expected Value | Joey |
|---|---|---|
| Implementation Required | html tag | html (iframe) |
| Coverage | All Notes | All Notes |
| User Reaction Recording | Anonymity , private user, no login | Anonymity , no private ,no login, |
| Customization Options | Not to much | title , placeholder , color |
| Integration Complexity | Low | Low |
| Cost | Affordable | Free up to 3 blocks(no limited response, block is component in Joey) |
| Operational Management | One Endpoint | one site (can see all history and users) |
Apply Google Analytics in bulk to all pages
src/site/_includes/layouts/note.njk
Initially, I attempted to insert an HTML script into all MD files, but I realized that it was too difficult. So, I looked for a template file that the MD files use to apply to the actual webpages
the template file is note.njk file
About Homepage is managed by index.njk
<!DOCTYPE html>
<html lang="{{ meta.mainLanguage }}">
<head>
...
{%include "components/pageheader.njk"%}
<!-- Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=G-QHF8SF84LT"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'G-QHF8SF84LT');
</script>
...
</head>
<body>
...
{{ content | hideDataview | link | taggify | safe}}
<!-- Iframe Content -->
<iframe src="https://joey.team/block/?id=4zfONMIb0udThRYvgsJesRl8BG13&block_id=LVHLMUlfRfZ9t0EyPdOI"
width="600"
height="400"
style="border: 10px solid #2e2e2e;border-radius: 10px;"
allowfullscreen>
</iframe>
...
</body>
</html>
Google Translation
Implementing Google Translation
Add script in position that after body's first 'end for'
After install, custom settings
Add Languages
Add a Border
Change location
Google Translation-CSS
.goog-te-gadget-simple {
font-size: 0.9em; /* Smaller font size might reduce the widget size */
display: inline-block; /* Ensures the widget takes only necessary space */
width: 80px; /* Or set a specific width if necessary */
height: 25px; /* Or set a specific height if necessary */
}
.goog-te-gadget-icon {
display: none; /* This can hide the dropdown icon, making the button simpler */
}
Google Translation-HTML
{% include imp %}
{% endfor %}
{{ content | hideDataview | link | taggify | safe}}
<!-- Google Translate div -->
<div id="google_translate_element" style="position: absolute; top: 20px; right: 20px;"></div>
<!-- Google Translate Initialization Script -->
<script type="text/javascript">
function googleTranslateElementInit() {
new google.translate.TranslateElement({pageLanguage: 'en', includedLanguages: 'en,ja,zh-CN,zh-TW'}, 'google_translate_element');
}
</script>
<!-- Google Translate API Script -->
<script type="text/javascript" src="//translate.google.com/translate_a/element.js?cb=googleTranslateElementInit"></script>
Hompage Custom
code font and color change
just code element not working so , important used
src/site/styles/custom-style.scss
code {
background-color: #c4b7b7 !important;
color: #1077ffcb !important;
padding: 2px !important;
font-weight: bolder !important;
}
# markdown badge image position
original is too much right
original is src/site/styles/obsidian-base.scss
.external-link {
color: var(--link-external-color);
text-decoration-line: var(--link-external-decoration);
background-position: center right;
background-repeat: no-repeat;
background-image: linear-gradient(transparent, transparent), url('/img/outgoing.svg');
background-size: 13px;
padding-right: 16px;
background-position-y: 4px;
cursor: var(--cursor-link);
filter: var(--link-external-filter);
}
Even I changed CSS, It's not applied. So i find the element and modify it.
markdown-rendered img
only works when using !important
add new line after badge
.markdown-rendered img {
float: left !important;
}
.external-link::after {
content: "";
display: block;
clear: both;
}
Change img soruce width and clear
p::before and clear
.markdown-rendered p::before {
content: ""; /* Creates a pseudo-element */
display: table; /* Ensures the content is treated as a block-level table */
clear: both; /* Clears the float */
}
add pre code block style
/*code block style test */
pre {
background-color: #f4f4f4; /* Light grey background */
border: 3px solid #d4c7c7b0; /* Light grey border */
border-left: 3px solid #f36d33; /* Highlighted left border for emphasis */
padding: 1em; /* Padding inside the pre element */
margin: 1em 0; /* Margin above and below the pre element */
overflow: auto; /* Adds a scrollbar if the content overflows */
font-family: 'Consolas', 'Monaco', 'Courier New', monospace; /* Monospaced font for better code readability */
white-space: pre-wrap; /* Ensures the text wraps and preserves spaces and line breaks */
word-break: break-all; /* Allows long words to be able to break and wrap onto the next line */
line-height: 1.5; /* Line height for better readability */
}
code and pre tags style by ai
/* Style for code blocks */
pre {
background-color: #f7f7f7; /* Light gray background */
border: 1px solid #e1e1e8; /* Light border color */
border-left: 4px solid #6699cc; /* Thicker left border for emphasis, blue color */
padding: 0.5em; /* Padding inside the pre element */
overflow-x: auto; /* Horizontal scrollbar if the content is too wide */
font-family: 'Consolas', 'Monaco', 'Courier New', monospace; /* Monospaced font for better readability */
white-space: pre; /* Preserves whitespace and line breaks as they are in the code */
color: #333; /* Dark grey color for the text */
}
/* Style for inline code */
code {
background-color: #eff0f1; /* Slightly different background color for inline code */
border: 1px solid #dcdcdc; /* Subtle border for inline code */
border-radius: 3px; /* Rounded corners for inline code */
padding: 0.2em 0.4em; /* Padding around the inline code */
font-family: 'Consolas', 'Monaco', 'Courier New', monospace; /* Monospaced font for better readability */
font-size: 0.9em; /* Slightly smaller font size for inline code */
color: #c7254e; /* Reddish color for the text, often used for inline code */
}
before
code {
background-color: #c4b7b7 !important;
color: #0146a1cb !important;
padding: 2px !important;
font-weight: bolder !important;
}
pre {
background-color: #f4f4f4; /* Light grey background */
border: 3px solid #d4c7c7b0; /* Light grey border */
border-left: 3px solid #f36d33; /* Highlighted left border for emphasis */
padding: 1em; /* Padding inside the pre element */
margin: 1em 0; /* Margin above and below the pre element */
overflow: auto; /* Adds a scrollbar if the content overflows */
font-family: 'Consolas', 'Monaco', 'Courier New', monospace; /* Monospaced font for better code readability */
white-space: pre-wrap; /* Ensures the text wraps and preserves spaces and line breaks */
word-break: break-all; /* Allows long words to be able to break and wrap onto the next line */
line-height: 1.5; /* Line height for better readability */
}
After
white background web site, so black window
.markdown-rendered pre code {
background-color: #242121; /* Black background for inline code */
color: #ff6347; /* Reddish color for text */
padding: 0.2em 0.4em;
border-radius: 3px;
font-family: 'Consolas', 'Monaco', 'Courier New', monospace;
font-size: 0.9em;
}
/* Specificity increased with .markdown-rendered to ensure override */
.markdown-rendered pre {
background-color: #000; /* Black background for code blocks */
color: #f5f5f5; /* Light grey, almost white color for text */
border-left: 4px solid #ff6347; /* Reddish color for the left border */
padding: 1em;
overflow: auto;
font-family: var(--font-monospace); /* Using the CSS variable for monospace font */
white-space: pre-wrap;
word-wrap: break-word;
border: none; /* Override any existing borders */
}
.markdown-rendered pre code {
/* Styles for inline code */
background-color: #000; /* Black background for inline code */
color: #ff6347; /* Reddish color for text */
padding: 0.2em 0.4em;
border: none; /* Remove border */
border-radius: 2px; /* Keep rounded corners if desired */
font-family: var(--font-monospace); /* Using the CSS variable for monospace font */
font-size: var(--code-size); /* Using the CSS variable for code size */
}
.markdown-rendered code {
/* Styles for inline code */
background-color: #000; /* Black background for inline code */
color: #ff6347; /* Reddish color for text */
padding: 0.2em 0.4em;
border: none; /* Remove border */
border-radius: 2px; /* Keep rounded corners if desired */
font-family: var(--font-monospace); /* Using the CSS variable for monospace font */
font-size: var(--code-size); /* Using the CSS variable for code size */
}
modify js and apply css
It seems like why css not wokred propery, maybe becasue of this wrong path in js function.
before
const STYLE_PATH = "src/site/styles/users";
after
const STYLE_PATH = "src/site/styles/";
const STYLE_PATH = "src/site/styles/";
// const generateStylesPaths = async () => {
// try {
// const tree = await fsFileTree(`${STYLE_PATH}`);
// let comps = Object.keys(tree).map((p) =>
// `/styles/user/${p}`.replace(".scss", ".css")
// );
// comps.sort();
// return comps;
// } catch {
// return [];
// }
// };
const generateStylesPaths = async () => {
try {
// Adjusted to the correct styles directory
const tree = await fsFileTree(`src/site/styles/`);
let comps = Object.keys(tree)
.map((p) => `/styles/${p}`.replace('.scss', '.css'))
// Remove custom-style.css if it's already in the array to re-add it later
.filter((path) => !path.endsWith('custom-style.css'));
// Sort the array to maintain a consistent order
comps.sort();
// Add custom-style.css at the end to ensure it's the last stylesheet
comps.push('/styles/custom-style.css');
return comps;
} catch {
return [];
}
};
hr for new line
In markdown --- horizon line makes new line. In html to makes new line defualt.
but my case not worked. So I inspect why, because no margin and padding in hr styles
So I just add it approximately 20px
I need to distinguish which HRs should have the style applied to that
If you're unsure about which tags are affected by a specific tag, you can use a developer tool like F12 to check.
.markdown-rendered hr {
margin-top: 20px; /* Adds 20 pixels of space above the <hr> */
margin-bottom: 20px; /* Adds 20 pixels of space below the <hr> */
}
Python Files
automation.py
conver_to json.
using one python file convert from md to json
structure.json
matching with current directory structure
create_base_template.py
For RAG, I thought there is need one default tempalte file, structure is 2 stages. first one is default parent file, and second is child file
) minor_regex = re.compile(r'^([0-9]{1}[1-9][0-9])\.mdMaking code
Think about data
when not major, convert major
when sub or book, consider position of function argument
{{CODE_BLOCK_9}}
Making tag
If you know how to use get for recursive contents in JSON, function become very easy
Understanding data structures and creating variables with JSON enables this recursive structure
0.2.3-OB
Change dataview query
TABLE file.name AS title, file.path, file.mtime
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
Add Table attrivutes modifed time path and remove link
Specifify query path "Projects/Library"
Increase Limit to 7
0.2.2-LB
Using GitHub to Share Synchronized Python Files Across Different Platforms
Problem
The current Obsidian sync functionality only supports synchronization for files with Python file extensions, excluding files in other formats such as Markdown (md).
Initial attempts involved converting Python files into Markdown (md) or inserting Python code into Markdown files. However, this approach resulted in excessive fragmentation and posed challenges for management.
Solution
https://github.com/murphybread/Library
To address this issue, the solution is to utilize GitHub links for syncing files between different platforms, such as Mac and Windows. This can be achieved by performing a 'git pull' to ensure synchronization with the latest version when starting work through the GitHub link.
0.2.1-PY
dg-publish frontmatter position
Problem
Notes not showing up on the homepage
Reasoning
There are some things that work and some things that don't, and in particular, there is a 404 in the case of the latter, so it seems that there is a problem with publishing.
If the tag of the note that doesn't work is separated by a line like this, it is judged as a problem.
problem form
Solution.
Tested some notes by moving the tags as follows and confirmed normal operation.
Then I added a function called update_content_and_position in the python file.
duplicate_tag.py to automate it.
{{CODE_BLOCK_12}}
0.2.0-PY
Change the call number index structure and modify the convert file
Problem
{{CODE_BLOCK_13}}
Major category indent was wrong
As-is Used this structure pattern
Major Category don't use hypen.
That makes preview error indent and line break
Solution
First Change call number md file like this
{{CODE_BLOCK_15}}
Second Change convert_josn.py
Important point is just change a little bit. Because I don't want to change output.json, filename, path etc...
only consider point is major and minor category variable.
{{CODE_BLOCK_16}}
0.1.1-PY
Managing Only Programming Files with .gitignore: Excluding Content Files
Problem
In the process of starting git pull first, a conflict issue occurs if there is a change in the content file.
It is appropriate to manage .md files other than .py only using the Sync function of the Obisidan tool.
Solution
- Delete .md files from remove server (when command is worked not delete immedately. you shoud commit and push)
- Register files with md extension (fileanme should be `.gitignore)
if command worked and file is created,
next step is commit and push
git commit -m "Managing Only Programming Files with .gitignore: Excluding Content Files"
git push
0.1.0-LB
automated tag from filename key point
This was hard because it is a backwards and forwards type, so if it is major.md, it is different from minor.md, sub.md, and books.md, and we aimed for a function that gets the value corresponding to the key in the structure.json file and processes it.
So, to simplify things a bit more, we went from filename-based to a situation where the exact filename is strictly enforced by the policy, and then we can automate it appropriately.
The key point is filenames, and only for content files.
Later on, we'll also apply it to uncharacterized category files, but that's for later...
0.0.4-OB
DataView modified
This query is used for Recent Post in homepage.
I delete file.path and add file.tags
tags doesn't display backlink tags
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
0.0.3-PY
Add Tag using structure,json in contents file
Adopting the approach of using filenames to create tag numbers was beneficial.
Upon updating to Dataview , I realized that attaching tags from book contents enhances usefulness.
Consequently, I integrated a 'booksTag' function.
Initially, I experimented with a function from another file, which utilized a 'title' variable.
However, to avoid dependencies, I ultimately developed the function within 'automation.py'.
I then opted to modify only a single function, as adding more could complicate matters. Incorporating the tagging functionality into an existing function proved sufficient.
0.0.2-OB
Modify the table to provide more useful information to the readers.
Easily see which files have been modified, and see the tags they have at a glance
- Change the standard modification time not the create time
file.ctime -> file.mtime - Exclude md file that have the tag
#Library
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library" AND -#Library
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 7
0.0.1-LB
The Library Cleaning
Changing History of Library.md from hardcoding to github gist
Better viewing of code on screen in the UI
Before
After
Initialize
0.0.0-LB
Major: The change creates a new process that may not work with the old process and requires significant consideration. Set version criteria more granularly
Keep major, which generally means not backwards compatible, intact
Minor: The change affects current processes and will require attention in the future. Minors are listed as feature additions. File creation, module additions, etc.
However, some minors may be incompatible. Because they don't mean exactly the same thing
For example, if a Python file in a certain version references example.txt, but you change it to base_template, it will not work in previous versions, but the purpose is for testing purposes, so it is considered MINOR in terms of impact.
Patch: The change is minimal or don't require much attention after the change. especially Patches are improvements such as variable names, bug fixes, refactorings, etc.
The reason for the change is that I didn't have an explicit criterion for considering the version impact, and now it's explicit.
분류
대분류 100,200,300
중분류 110,120,130
소분류 101.10 101.20 101.30
중요한것 방향성, 확장성, 기준, 관리
방향성: 인프라 100, 인프라위에 올라가는 cicd 200, cicd를 활용한 위에 올라가는 또는 고급 300등방향성
확장성: 새 주제나 개념이 번호가 붙을 때 중간에 밀어내야하는 경우 ex) 110(A) 120(B)에서 110(A) 120(C) 130(B)으로 확장할경우 110(A) 111(B) 120(B)를 통해 유연하게 확장 가능
-> 이전 버전인 101,102형태면 불가
유사 분류는 뒤에 알파벳을 붙임. 즉 알파벳의 경우 일부러 방향성을 정하지 않음. 110에 해당하지만 그렇다고 110.1처럼 하위로 나누기는 애매한거에 붙임
기준: 확장성을 살려도 110이나 120에대한 개념이 바뀌면 안되기에 최대한 신중하게 골라야 가능. 예를들어 111에 못넣고 기존의 120을 대체해야하는 경우, 기존의120이 121로 밀리게됨 즉 추가가 아니라 기존 데이터도 변동
ADD-Ons
Guest book
problem: record reaction of users in all notes
solution: using external service joey
| Feature | Expected Value | Joey |
|---|---|---|
| Implementation Required | html tag | html (iframe) |
| Coverage | All Notes | All Notes |
| User Reaction Recording | Anonymity , private user, no login | Anonymity , no private ,no login, |
| Customization Options | Not to much | title , placeholder , color |
| Integration Complexity | Low | Low |
| Cost | Affordable | Free up to 3 blocks(no limited response, block is component in Joey) |
| Operational Management | One Endpoint | one site (can see all history and users) |
Apply Google Analytics in bulk to all pages
src/site/_includes/layouts/note.njk
Initially, I attempted to insert an HTML script into all MD files, but I realized that it was too difficult. So, I looked for a template file that the MD files use to apply to the actual webpages
the template file is note.njk file
About Homepage is managed by index.njk
{{CODE_BLOCK_19}}
Google Translation
Implementing Google Translation
Add script in position that after body's first 'end for'
After install, custom settings
Add Languages
Add a Border
Change location
Google Translation-CSS
{{CODE_BLOCK_20}}
Google Translation-HTML
{{CODE_BLOCK_21}}
Hompage Custom
code font and color change
just code element not working so , important used
src/site/styles/custom-style.scss
{{CODE_BLOCK_22}}
{{CODE_BLOCK_23}}
Even I changed CSS, It's not applied. So i find the element and modify it.
markdown-rendered img
only works when using !important
add new line after badge
Change img soruce width and clear
p::before and clear
add pre code block style
{{CODE_BLOCK_26}}
code and pre tags style by ai
{{CODE_BLOCK_27}}
before
After
white background web site, so black window
modify js and apply css
It seems like why css not wokred propery, maybe becasue of this wrong path in js function.
before
const STYLE_PATH = "src/site/styles/users";
after
const STYLE_PATH = "src/site/styles/";
{{CODE_BLOCK_30}}
hr for new line
In markdown --- horizon line makes new line. In html to makes new line defualt.
but my case not worked. So I inspect why, because no margin and padding in hr styles
So I just add it approximately 20px
I need to distinguish which HRs should have the style applied to that
If you're unsure about which tags are affected by a specific tag, you can use a developer tool like F12 to check.
{{CODE_BLOCK_31}}
Python Files
automation.py
conver_to json.
using one python file convert from md to json
structure.json
matching with current directory structure
create_base_template.py
For RAG, I thought there is need one default tempalte file, structure is 2 stages. first one is default parent file, and second is child file
) subcategory_regex = re.compile(r'^([0-9]{1}[1-9][0-9])\.([0-9]{2})\.mdMaking code
Think about data
when not major, convert major
when sub or book, consider position of function argument
{{CODE_BLOCK_9}}
Making tag
If you know how to use get for recursive contents in JSON, function become very easy
Understanding data structures and creating variables with JSON enables this recursive structure
0.2.3-OB
Change dataview query
TABLE file.name AS title, file.path, file.mtime
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
Add Table attrivutes modifed time path and remove link
Specifify query path "Projects/Library"
Increase Limit to 7
0.2.2-LB
Using GitHub to Share Synchronized Python Files Across Different Platforms
Problem
The current Obsidian sync functionality only supports synchronization for files with Python file extensions, excluding files in other formats such as Markdown (md).
Initial attempts involved converting Python files into Markdown (md) or inserting Python code into Markdown files. However, this approach resulted in excessive fragmentation and posed challenges for management.
Solution
https://github.com/murphybread/Library
To address this issue, the solution is to utilize GitHub links for syncing files between different platforms, such as Mac and Windows. This can be achieved by performing a 'git pull' to ensure synchronization with the latest version when starting work through the GitHub link.
0.2.1-PY
dg-publish frontmatter position
Problem
Notes not showing up on the homepage
Reasoning
There are some things that work and some things that don't, and in particular, there is a 404 in the case of the latter, so it seems that there is a problem with publishing.
If the tag of the note that doesn't work is separated by a line like this, it is judged as a problem.
problem form
Solution.
Tested some notes by moving the tags as follows and confirmed normal operation.
Then I added a function called update_content_and_position in the python file.
duplicate_tag.py to automate it.
{{CODE_BLOCK_12}}
0.2.0-PY
Change the call number index structure and modify the convert file
Problem
{{CODE_BLOCK_13}}
Major category indent was wrong
As-is Used this structure pattern
Major Category don't use hypen.
That makes preview error indent and line break
Solution
First Change call number md file like this
{{CODE_BLOCK_15}}
Second Change convert_josn.py
Important point is just change a little bit. Because I don't want to change output.json, filename, path etc...
only consider point is major and minor category variable.
{{CODE_BLOCK_16}}
0.1.1-PY
Managing Only Programming Files with .gitignore: Excluding Content Files
Problem
In the process of starting git pull first, a conflict issue occurs if there is a change in the content file.
It is appropriate to manage .md files other than .py only using the Sync function of the Obisidan tool.
Solution
- Delete .md files from remove server (when command is worked not delete immedately. you shoud commit and push)
- Register files with md extension (fileanme should be `.gitignore)
if command worked and file is created,
next step is commit and push
git commit -m "Managing Only Programming Files with .gitignore: Excluding Content Files"
git push
0.1.0-LB
automated tag from filename key point
This was hard because it is a backwards and forwards type, so if it is major.md, it is different from minor.md, sub.md, and books.md, and we aimed for a function that gets the value corresponding to the key in the structure.json file and processes it.
So, to simplify things a bit more, we went from filename-based to a situation where the exact filename is strictly enforced by the policy, and then we can automate it appropriately.
The key point is filenames, and only for content files.
Later on, we'll also apply it to uncharacterized category files, but that's for later...
0.0.4-OB
DataView modified
This query is used for Recent Post in homepage.
I delete file.path and add file.tags
tags doesn't display backlink tags
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
0.0.3-PY
Add Tag using structure,json in contents file
Adopting the approach of using filenames to create tag numbers was beneficial.
Upon updating to Dataview , I realized that attaching tags from book contents enhances usefulness.
Consequently, I integrated a 'booksTag' function.
Initially, I experimented with a function from another file, which utilized a 'title' variable.
However, to avoid dependencies, I ultimately developed the function within 'automation.py'.
I then opted to modify only a single function, as adding more could complicate matters. Incorporating the tagging functionality into an existing function proved sufficient.
0.0.2-OB
Modify the table to provide more useful information to the readers.
Easily see which files have been modified, and see the tags they have at a glance
- Change the standard modification time not the create time
file.ctime -> file.mtime - Exclude md file that have the tag
#Library
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library" AND -#Library
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 7
0.0.1-LB
The Library Cleaning
Changing History of Library.md from hardcoding to github gist
Better viewing of code on screen in the UI
Before
After
Initialize
0.0.0-LB
Major: The change creates a new process that may not work with the old process and requires significant consideration. Set version criteria more granularly
Keep major, which generally means not backwards compatible, intact
Minor: The change affects current processes and will require attention in the future. Minors are listed as feature additions. File creation, module additions, etc.
However, some minors may be incompatible. Because they don't mean exactly the same thing
For example, if a Python file in a certain version references example.txt, but you change it to base_template, it will not work in previous versions, but the purpose is for testing purposes, so it is considered MINOR in terms of impact.
Patch: The change is minimal or don't require much attention after the change. especially Patches are improvements such as variable names, bug fixes, refactorings, etc.
The reason for the change is that I didn't have an explicit criterion for considering the version impact, and now it's explicit.
분류
대분류 100,200,300
중분류 110,120,130
소분류 101.10 101.20 101.30
중요한것 방향성, 확장성, 기준, 관리
방향성: 인프라 100, 인프라위에 올라가는 cicd 200, cicd를 활용한 위에 올라가는 또는 고급 300등방향성
확장성: 새 주제나 개념이 번호가 붙을 때 중간에 밀어내야하는 경우 ex) 110(A) 120(B)에서 110(A) 120(C) 130(B)으로 확장할경우 110(A) 111(B) 120(B)를 통해 유연하게 확장 가능
-> 이전 버전인 101,102형태면 불가
유사 분류는 뒤에 알파벳을 붙임. 즉 알파벳의 경우 일부러 방향성을 정하지 않음. 110에 해당하지만 그렇다고 110.1처럼 하위로 나누기는 애매한거에 붙임
기준: 확장성을 살려도 110이나 120에대한 개념이 바뀌면 안되기에 최대한 신중하게 골라야 가능. 예를들어 111에 못넣고 기존의 120을 대체해야하는 경우, 기존의120이 121로 밀리게됨 즉 추가가 아니라 기존 데이터도 변동
ADD-Ons
Guest book
problem: record reaction of users in all notes
solution: using external service joey
| Feature | Expected Value | Joey |
|---|---|---|
| Implementation Required | html tag | html (iframe) |
| Coverage | All Notes | All Notes |
| User Reaction Recording | Anonymity , private user, no login | Anonymity , no private ,no login, |
| Customization Options | Not to much | title , placeholder , color |
| Integration Complexity | Low | Low |
| Cost | Affordable | Free up to 3 blocks(no limited response, block is component in Joey) |
| Operational Management | One Endpoint | one site (can see all history and users) |
Apply Google Analytics in bulk to all pages
src/site/_includes/layouts/note.njk
Initially, I attempted to insert an HTML script into all MD files, but I realized that it was too difficult. So, I looked for a template file that the MD files use to apply to the actual webpages
the template file is note.njk file
About Homepage is managed by index.njk
{{CODE_BLOCK_19}}
Google Translation
Implementing Google Translation
Add script in position that after body's first 'end for'
After install, custom settings
Add Languages
Add a Border
Change location
Google Translation-CSS
{{CODE_BLOCK_20}}
Google Translation-HTML
{{CODE_BLOCK_21}}
Hompage Custom
code font and color change
just code element not working so , important used
src/site/styles/custom-style.scss
{{CODE_BLOCK_22}}
{{CODE_BLOCK_23}}
Even I changed CSS, It's not applied. So i find the element and modify it.
markdown-rendered img
only works when using !important
add new line after badge
Change img soruce width and clear
p::before and clear
add pre code block style
{{CODE_BLOCK_26}}
code and pre tags style by ai
{{CODE_BLOCK_27}}
before
After
white background web site, so black window
modify js and apply css
It seems like why css not wokred propery, maybe becasue of this wrong path in js function.
before
const STYLE_PATH = "src/site/styles/users";
after
const STYLE_PATH = "src/site/styles/";
{{CODE_BLOCK_30}}
hr for new line
In markdown --- horizon line makes new line. In html to makes new line defualt.
but my case not worked. So I inspect why, because no margin and padding in hr styles
So I just add it approximately 20px
I need to distinguish which HRs should have the style applied to that
If you're unsure about which tags are affected by a specific tag, you can use a developer tool like F12 to check.
{{CODE_BLOCK_31}}
Python Files
automation.py
conver_to json.
using one python file convert from md to json
structure.json
matching with current directory structure
create_base_template.py
For RAG, I thought there is need one default tempalte file, structure is 2 stages. first one is default parent file, and second is child file
) book_regex = re.compile(r'^([0-9]{1}[1-9][0-9])\.([0-9]{2})\s([a-z])\.mdMaking code
Think about data
when not major, convert major
when sub or book, consider position of function argument
{{CODE_BLOCK_9}}
Making tag
If you know how to use get for recursive contents in JSON, function become very easy
Understanding data structures and creating variables with JSON enables this recursive structure
0.2.3-OB
Change dataview query
TABLE file.name AS title, file.path, file.mtime
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
Add Table attrivutes modifed time path and remove link
Specifify query path "Projects/Library"
Increase Limit to 7
0.2.2-LB
Using GitHub to Share Synchronized Python Files Across Different Platforms
Problem
The current Obsidian sync functionality only supports synchronization for files with Python file extensions, excluding files in other formats such as Markdown (md).
Initial attempts involved converting Python files into Markdown (md) or inserting Python code into Markdown files. However, this approach resulted in excessive fragmentation and posed challenges for management.
Solution
https://github.com/murphybread/Library
To address this issue, the solution is to utilize GitHub links for syncing files between different platforms, such as Mac and Windows. This can be achieved by performing a 'git pull' to ensure synchronization with the latest version when starting work through the GitHub link.
0.2.1-PY
dg-publish frontmatter position
Problem
Notes not showing up on the homepage
Reasoning
There are some things that work and some things that don't, and in particular, there is a 404 in the case of the latter, so it seems that there is a problem with publishing.
If the tag of the note that doesn't work is separated by a line like this, it is judged as a problem.
problem form
Solution.
Tested some notes by moving the tags as follows and confirmed normal operation.
Then I added a function called update_content_and_position in the python file.
duplicate_tag.py to automate it.
{{CODE_BLOCK_12}}
0.2.0-PY
Change the call number index structure and modify the convert file
Problem
{{CODE_BLOCK_13}}
Major category indent was wrong
As-is Used this structure pattern
Major Category don't use hypen.
That makes preview error indent and line break
Solution
First Change call number md file like this
{{CODE_BLOCK_15}}
Second Change convert_josn.py
Important point is just change a little bit. Because I don't want to change output.json, filename, path etc...
only consider point is major and minor category variable.
{{CODE_BLOCK_16}}
0.1.1-PY
Managing Only Programming Files with .gitignore: Excluding Content Files
Problem
In the process of starting git pull first, a conflict issue occurs if there is a change in the content file.
It is appropriate to manage .md files other than .py only using the Sync function of the Obisidan tool.
Solution
- Delete .md files from remove server (when command is worked not delete immedately. you shoud commit and push)
- Register files with md extension (fileanme should be `.gitignore)
if command worked and file is created,
next step is commit and push
git commit -m "Managing Only Programming Files with .gitignore: Excluding Content Files"
git push
0.1.0-LB
automated tag from filename key point
This was hard because it is a backwards and forwards type, so if it is major.md, it is different from minor.md, sub.md, and books.md, and we aimed for a function that gets the value corresponding to the key in the structure.json file and processes it.
So, to simplify things a bit more, we went from filename-based to a situation where the exact filename is strictly enforced by the policy, and then we can automate it appropriately.
The key point is filenames, and only for content files.
Later on, we'll also apply it to uncharacterized category files, but that's for later...
0.0.4-OB
DataView modified
This query is used for Recent Post in homepage.
I delete file.path and add file.tags
tags doesn't display backlink tags
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
0.0.3-PY
Add Tag using structure,json in contents file
Adopting the approach of using filenames to create tag numbers was beneficial.
Upon updating to Dataview , I realized that attaching tags from book contents enhances usefulness.
Consequently, I integrated a 'booksTag' function.
Initially, I experimented with a function from another file, which utilized a 'title' variable.
However, to avoid dependencies, I ultimately developed the function within 'automation.py'.
I then opted to modify only a single function, as adding more could complicate matters. Incorporating the tagging functionality into an existing function proved sufficient.
0.0.2-OB
Modify the table to provide more useful information to the readers.
Easily see which files have been modified, and see the tags they have at a glance
- Change the standard modification time not the create time
file.ctime -> file.mtime - Exclude md file that have the tag
#Library
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library" AND -#Library
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 7
0.0.1-LB
The Library Cleaning
Changing History of Library.md from hardcoding to github gist
Better viewing of code on screen in the UI
Before
After
Initialize
0.0.0-LB
Major: The change creates a new process that may not work with the old process and requires significant consideration. Set version criteria more granularly
Keep major, which generally means not backwards compatible, intact
Minor: The change affects current processes and will require attention in the future. Minors are listed as feature additions. File creation, module additions, etc.
However, some minors may be incompatible. Because they don't mean exactly the same thing
For example, if a Python file in a certain version references example.txt, but you change it to base_template, it will not work in previous versions, but the purpose is for testing purposes, so it is considered MINOR in terms of impact.
Patch: The change is minimal or don't require much attention after the change. especially Patches are improvements such as variable names, bug fixes, refactorings, etc.
The reason for the change is that I didn't have an explicit criterion for considering the version impact, and now it's explicit.
분류
대분류 100,200,300
중분류 110,120,130
소분류 101.10 101.20 101.30
중요한것 방향성, 확장성, 기준, 관리
방향성: 인프라 100, 인프라위에 올라가는 cicd 200, cicd를 활용한 위에 올라가는 또는 고급 300등방향성
확장성: 새 주제나 개념이 번호가 붙을 때 중간에 밀어내야하는 경우 ex) 110(A) 120(B)에서 110(A) 120(C) 130(B)으로 확장할경우 110(A) 111(B) 120(B)를 통해 유연하게 확장 가능
-> 이전 버전인 101,102형태면 불가
유사 분류는 뒤에 알파벳을 붙임. 즉 알파벳의 경우 일부러 방향성을 정하지 않음. 110에 해당하지만 그렇다고 110.1처럼 하위로 나누기는 애매한거에 붙임
기준: 확장성을 살려도 110이나 120에대한 개념이 바뀌면 안되기에 최대한 신중하게 골라야 가능. 예를들어 111에 못넣고 기존의 120을 대체해야하는 경우, 기존의120이 121로 밀리게됨 즉 추가가 아니라 기존 데이터도 변동
ADD-Ons
Guest book
problem: record reaction of users in all notes
solution: using external service joey
| Feature | Expected Value | Joey |
|---|---|---|
| Implementation Required | html tag | html (iframe) |
| Coverage | All Notes | All Notes |
| User Reaction Recording | Anonymity , private user, no login | Anonymity , no private ,no login, |
| Customization Options | Not to much | title , placeholder , color |
| Integration Complexity | Low | Low |
| Cost | Affordable | Free up to 3 blocks(no limited response, block is component in Joey) |
| Operational Management | One Endpoint | one site (can see all history and users) |
Apply Google Analytics in bulk to all pages
src/site/_includes/layouts/note.njk
Initially, I attempted to insert an HTML script into all MD files, but I realized that it was too difficult. So, I looked for a template file that the MD files use to apply to the actual webpages
the template file is note.njk file
About Homepage is managed by index.njk
{{CODE_BLOCK_19}}
Google Translation
Implementing Google Translation
Add script in position that after body's first 'end for'
After install, custom settings
Add Languages
Add a Border
Change location
Google Translation-CSS
{{CODE_BLOCK_20}}
Google Translation-HTML
{{CODE_BLOCK_21}}
Hompage Custom
code font and color change
just code element not working so , important used
src/site/styles/custom-style.scss
{{CODE_BLOCK_22}}
{{CODE_BLOCK_23}}
Even I changed CSS, It's not applied. So i find the element and modify it.
markdown-rendered img
only works when using !important
add new line after badge
Change img soruce width and clear
p::before and clear
add pre code block style
{{CODE_BLOCK_26}}
code and pre tags style by ai
{{CODE_BLOCK_27}}
before
After
white background web site, so black window
modify js and apply css
It seems like why css not wokred propery, maybe becasue of this wrong path in js function.
before
const STYLE_PATH = "src/site/styles/users";
after
const STYLE_PATH = "src/site/styles/";
{{CODE_BLOCK_30}}
hr for new line
In markdown --- horizon line makes new line. In html to makes new line defualt.
but my case not worked. So I inspect why, because no margin and padding in hr styles
So I just add it approximately 20px
I need to distinguish which HRs should have the style applied to that
If you're unsure about which tags are affected by a specific tag, you can use a developer tool like F12 to check.
{{CODE_BLOCK_31}}
Python Files
automation.py
conver_to json.
using one python file convert from md to json
structure.json
matching with current directory structure
create_base_template.py
For RAG, I thought there is need one default tempalte file, structure is 2 stages. first one is default parent file, and second is child file
, re.IGNORECASE) ```Making code
Think about data
when not major, convert major
when sub or book, consider position of function argument
{{CODE_BLOCK_9}}
Making tag
If you know how to use get for recursive contents in JSON, function become very easy
Understanding data structures and creating variables with JSON enables this recursive structure
0.2.3-OB
Change dataview query
TABLE file.name AS title, file.path, file.mtime
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
Add Table attrivutes modifed time path and remove link
Specifify query path "Projects/Library"
Increase Limit to 7
0.2.2-LB
Using GitHub to Share Synchronized Python Files Across Different Platforms
Problem
The current Obsidian sync functionality only supports synchronization for files with Python file extensions, excluding files in other formats such as Markdown (md).
Initial attempts involved converting Python files into Markdown (md) or inserting Python code into Markdown files. However, this approach resulted in excessive fragmentation and posed challenges for management.
Solution
https://github.com/murphybread/Library
To address this issue, the solution is to utilize GitHub links for syncing files between different platforms, such as Mac and Windows. This can be achieved by performing a 'git pull' to ensure synchronization with the latest version when starting work through the GitHub link.
0.2.1-PY
dg-publish frontmatter position
Problem
Notes not showing up on the homepage
Reasoning
There are some things that work and some things that don't, and in particular, there is a 404 in the case of the latter, so it seems that there is a problem with publishing.
If the tag of the note that doesn't work is separated by a line like this, it is judged as a problem.
problem form
Solution.
Tested some notes by moving the tags as follows and confirmed normal operation.
Then I added a function called update_content_and_position in the python file.
duplicate_tag.py to automate it.
{{CODE_BLOCK_12}}
0.2.0-PY
Change the call number index structure and modify the convert file
Problem
{{CODE_BLOCK_13}}
Major category indent was wrong
As-is Used this structure pattern
Major Category don't use hypen.
That makes preview error indent and line break
Solution
First Change call number md file like this
{{CODE_BLOCK_15}}
Second Change convert_josn.py
Important point is just change a little bit. Because I don't want to change output.json, filename, path etc...
only consider point is major and minor category variable.
{{CODE_BLOCK_16}}
0.1.1-PY
Managing Only Programming Files with .gitignore: Excluding Content Files
Problem
In the process of starting git pull first, a conflict issue occurs if there is a change in the content file.
It is appropriate to manage .md files other than .py only using the Sync function of the Obisidan tool.
Solution
- Delete .md files from remove server (when command is worked not delete immedately. you shoud commit and push)
- Register files with md extension (fileanme should be `.gitignore)
if command worked and file is created,
next step is commit and push
git commit -m "Managing Only Programming Files with .gitignore: Excluding Content Files"
git push
0.1.0-LB
automated tag from filename key point
This was hard because it is a backwards and forwards type, so if it is major.md, it is different from minor.md, sub.md, and books.md, and we aimed for a function that gets the value corresponding to the key in the structure.json file and processes it.
So, to simplify things a bit more, we went from filename-based to a situation where the exact filename is strictly enforced by the policy, and then we can automate it appropriately.
The key point is filenames, and only for content files.
Later on, we'll also apply it to uncharacterized category files, but that's for later...
0.0.4-OB
DataView modified
This query is used for Recent Post in homepage.
I delete file.path and add file.tags
tags doesn't display backlink tags
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library"
WHERE dg-publish = true
SORT file.ctime DESC
LIMIT 7
0.0.3-PY
Add Tag using structure,json in contents file
Adopting the approach of using filenames to create tag numbers was beneficial.
Upon updating to Dataview , I realized that attaching tags from book contents enhances usefulness.
Consequently, I integrated a 'booksTag' function.
Initially, I experimented with a function from another file, which utilized a 'title' variable.
However, to avoid dependencies, I ultimately developed the function within 'automation.py'.
I then opted to modify only a single function, as adding more could complicate matters. Incorporating the tagging functionality into an existing function proved sufficient.
0.0.2-OB
Modify the table to provide more useful information to the readers.
Easily see which files have been modified, and see the tags they have at a glance
- Change the standard modification time not the create time
file.ctime -> file.mtime - Exclude md file that have the tag
#Library
TABLE file.name AS Title, file.tags AS Tags
FROM "Projects/Library" AND -#Library
WHERE dg-publish = true
SORT file.mtime DESC
LIMIT 7
0.0.1-LB
The Library Cleaning
Changing History of Library.md from hardcoding to github gist
Better viewing of code on screen in the UI
Before
After
Initialize
0.0.0-LB
Major: The change creates a new process that may not work with the old process and requires significant consideration. Set version criteria more granularly
Keep major, which generally means not backwards compatible, intact
Minor: The change affects current processes and will require attention in the future. Minors are listed as feature additions. File creation, module additions, etc.
However, some minors may be incompatible. Because they don't mean exactly the same thing
For example, if a Python file in a certain version references example.txt, but you change it to base_template, it will not work in previous versions, but the purpose is for testing purposes, so it is considered MINOR in terms of impact.
Patch: The change is minimal or don't require much attention after the change. especially Patches are improvements such as variable names, bug fixes, refactorings, etc.
The reason for the change is that I didn't have an explicit criterion for considering the version impact, and now it's explicit.
분류
대분류 100,200,300
중분류 110,120,130
소분류 101.10 101.20 101.30
중요한것 방향성, 확장성, 기준, 관리
방향성: 인프라 100, 인프라위에 올라가는 cicd 200, cicd를 활용한 위에 올라가는 또는 고급 300등방향성
확장성: 새 주제나 개념이 번호가 붙을 때 중간에 밀어내야하는 경우 ex) 110(A) 120(B)에서 110(A) 120(C) 130(B)으로 확장할경우 110(A) 111(B) 120(B)를 통해 유연하게 확장 가능
-> 이전 버전인 101,102형태면 불가
유사 분류는 뒤에 알파벳을 붙임. 즉 알파벳의 경우 일부러 방향성을 정하지 않음. 110에 해당하지만 그렇다고 110.1처럼 하위로 나누기는 애매한거에 붙임
기준: 확장성을 살려도 110이나 120에대한 개념이 바뀌면 안되기에 최대한 신중하게 골라야 가능. 예를들어 111에 못넣고 기존의 120을 대체해야하는 경우, 기존의120이 121로 밀리게됨 즉 추가가 아니라 기존 데이터도 변동
ADD-Ons
Guest book
problem: record reaction of users in all notes
solution: using external service joey
| Feature | Expected Value | Joey |
|---|---|---|
| Implementation Required | html tag | html (iframe) |
| Coverage | All Notes | All Notes |
| User Reaction Recording | Anonymity , private user, no login | Anonymity , no private ,no login, |
| Customization Options | Not to much | title , placeholder , color |
| Integration Complexity | Low | Low |
| Cost | Affordable | Free up to 3 blocks(no limited response, block is component in Joey) |
| Operational Management | One Endpoint | one site (can see all history and users) |
Apply Google Analytics in bulk to all pages
src/site/_includes/layouts/note.njk
Initially, I attempted to insert an HTML script into all MD files, but I realized that it was too difficult. So, I looked for a template file that the MD files use to apply to the actual webpages
the template file is note.njk file
About Homepage is managed by index.njk
{{CODE_BLOCK_19}}
Google Translation
Implementing Google Translation
Add script in position that after body's first 'end for'
After install, custom settings
Add Languages
Add a Border
Change location
Google Translation-CSS
{{CODE_BLOCK_20}}
Google Translation-HTML
{{CODE_BLOCK_21}}
Hompage Custom
code font and color change
just code element not working so , important used
src/site/styles/custom-style.scss
{{CODE_BLOCK_22}}
{{CODE_BLOCK_23}}
Even I changed CSS, It's not applied. So i find the element and modify it.
markdown-rendered img
only works when using !important
add new line after badge
Change img soruce width and clear
p::before and clear
add pre code block style
{{CODE_BLOCK_26}}
code and pre tags style by ai
{{CODE_BLOCK_27}}
before
After
white background web site, so black window
modify js and apply css
It seems like why css not wokred propery, maybe becasue of this wrong path in js function.
before
const STYLE_PATH = "src/site/styles/users";
after
const STYLE_PATH = "src/site/styles/";
{{CODE_BLOCK_30}}
hr for new line
In markdown --- horizon line makes new line. In html to makes new line defualt.
but my case not worked. So I inspect why, because no margin and padding in hr styles
So I just add it approximately 20px
I need to distinguish which HRs should have the style applied to that
If you're unsure about which tags are affected by a specific tag, you can use a developer tool like F12 to check.
{{CODE_BLOCK_31}}
Python Files
automation.py
conver_to json.
using one python file convert from md to json
structure.json
matching with current directory structure
create_base_template.py
For RAG, I thought there is need one default tempalte file, structure is 2 stages. first one is default parent file, and second is child file