gemini flash 2.0 으로 일관된 그림체의 캐릭터 그려보기
Description: 이미지-텍스트 모달리티를 가진 LLM을 통해 inpaint 적인 내용과 consistent 적인 내용을 테스트해봅니다.
현재 노트: KR-P-120 b gemini flash 2.0 으로 일관된 그림체의 캐릭터 그려보기
상위 분류: KR-P-120 취미
Text to Image로 그림을 그리기가 가능한 경우는 많습니다.
하지만 Natural language를 이해하는 경우는 별로 없습니다.
거기에 inpaint적인 요소와 image read까지 가능한 경우라면 훨씬희소해 집니다.
모델자체가 많이 없을뿐더러 가격또한 만만치 않습니다.
하지만 최근에 이런 모든 기능을 지원하는 모델이 무료료 사용가능하게 되면서 테스트해보았습니다.
https://developers.googleblog.com/en/experiment-with-gemini-20-flash-native-image-generation/
해당 테이블 기준으로 free티어의 경우 분당 약 10요청으로 충분히 쓸만한 상태입니다.
https://ai.google.dev/gemini-api/docs/rate-limits#current-rate-limits
| Model | RPM | TPM | RPD |
|---|---|---|---|
| Gemini 2.0 Flash | 15 | 1,000,000 | 1,500 |
| Gemini 2.0 Flash-Lite | 30 | 1,000,000 | 1,500 |
| Gemini 2.0 Pro Experimental 02-05 | 2 | 1,000,000 | 50 |
| Gemini 2.0 Flash Thinking Experimental 01-21 | 10 | 4,000,000 | 1,500 |
| Gemini 1.5 Flash | 15 | 1,000,000 | 1,500 |
| Gemini 1.5 Flash-8B | 15 | 1,000,000 | 1,500 |
| Gemini 1.5 Pro | 2 | 32,000 | 50 |
| Imagen 3 | -- | -- | -- |
geminai 2.0 flash exp 그림 요청 스타일
I want a single drawing, in black and white, with a rough sketchy look, no fine details.I need you to do one drawing in black and white only, with a rough sketchy feel to it. No fine details, just some blurred lines and a rough feel.
Don't color too densely.
The whole body of the person should be shown. A bit of a Japanese manga style mixed with a webtoon style.
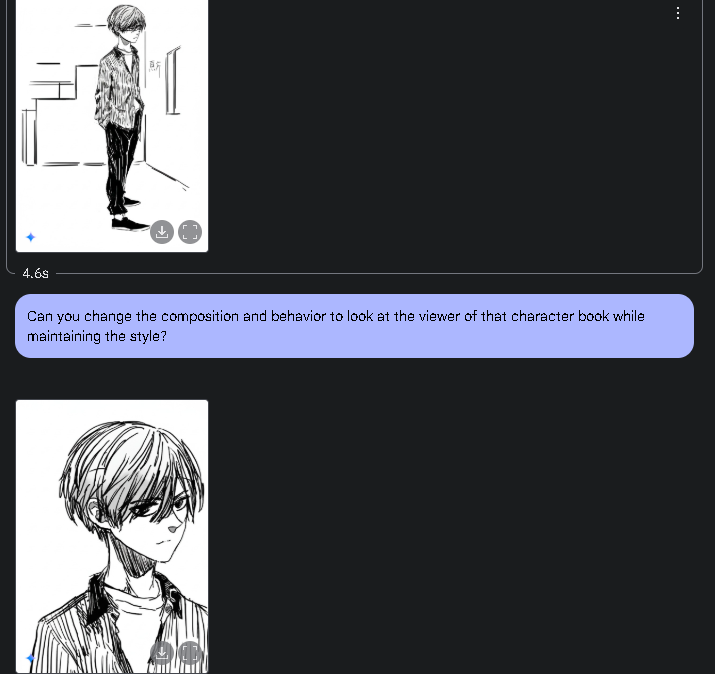
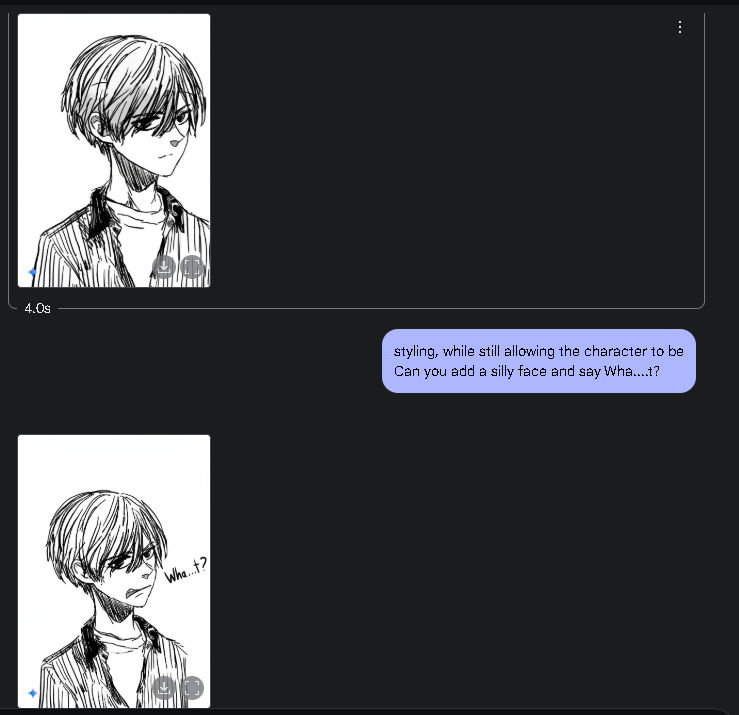
캐릭터 유지하며 그리기 프롬프트 whole. style and character
Okay, here are the common style and character prompts that were likely interpreted and used to generate the sequence of images, based on your requests:
Common Style Prompts:
"black and white" / "in black and white only": This clearly defines the color palette.
"rough sketchy look" / "rough sketchy feel": This directs the AI to avoid smooth lines and detailed rendering, aiming for a more hand-drawn, unrefined appearance.
"no fine details": This reinforces the idea of a simplified style, focusing on core shapes and outlines rather than intricate elements.
"some blurred lines": This suggests a lack of sharp definition and potentially some implied movement or lack of focus.
"Don't color too densely": Even though it's black and white, this implies a sparse application of shading, avoiding large solid areas of black.
"Japanese manga style": This points towards characteristic manga features like expressive eyes (though simplified here), slightly stylized proportions, and dynamic line work.
"mixed with a webtoon style": Webtoon style often shares similarities with manga but can sometimes have slightly simpler line work and coloring (though coloring wasn't used here). It also often focuses on full-body shots for scrolling.
Common Character Prompts:
"The whole body of the person should be shown": This dictated the initial full-figure composition.
"A bit of a Japanese manga style mixed with a webtoon style": This influenced the overall look of the character, including potential facial features and body proportions (though these were kept relatively simple due to the "no fine details" constraint).
"[describe specific appearance details here: e.g., a young man with messy hair and a slightly downcast gaze, wearing a loose-fitting striped shirt and pants, hands in pockets]": While you didn't explicitly give all these details in one go, these are the types of character details that were interpreted and maintained throughout the evolution of the image. The striped shirt was a consistent feature.
"looking at the viewer": This changed the character's gaze and created a direct connection with the audience.
"silly face": This prompted a change in the facial expression to something more exaggerated and humorous.
"say Wha....t?": This requested the addition of text indicating surprise or disbelief, further emphasizing the silly expression.
Implicit Prompts (Inferred by the AI based on the combination of requests):
A single character as the focus.
Relatively simple clothing and features to match the sketchy style.
The character's emotional state evolving based on the requested actions and expressions.
By using a combination of these style and character prompts, you guided the AI to create the specific images you envisioned. Remember that the exact interpretation of these prompts can vary slightly between different AI image generation models.
여기서 주목해볼만한 점은 해당 인물의 consistent가 유지디면서 원하는 스타일로 그림이 그려진다는점입니다.
이런 LLM 모델을 사용한다면 추후에 다른 요소랑 결합한다면 원하는 그림을 좀 더 일관성있게 그리는 보조자로 사용가능할 것이다라고 생각합니다.